Multilingual Projects on the NLG Platform
Translating, just like writing, did not scale in the past. The production of translations was as dependent on the number of translators involved, as much as text production was on its writers.
The NLG Platform provides good conditions for the distribution of multilingual content. More than 100 languages are currently available on the platform (plus different versions for countries and regions).
What to Expect From This Guide?
In this guide you will learn how to plan and setup a project on the NLG Platform that can generate results in multiple languages.
It also covers the preparatory considerations and steps you need to take. Since setting up logic and conditions in Transform as well as using branches and containers in Write are essentially the same in multilingual projects as in monolingual projects, there are no lessons on the platform in this guide.
The prerequisite for this guide is the AX Seminar.
(Machine) Translation vs Automated Text Generation
Today there are two automated solutions for translation available: on the one hand automated translation (also machine translation), and on the other hand, the automated multilingual text production.
Automated text generation is not equal to automated translation. In automated translation, finished texts in one language are translated by a machine, to one or more languages. It's roughly the same as using machine translation tools such as DeepL or Google Translate instead of human translators. You put in a finished text, choose your source language, and then get the translation. This means the finished text from the main language is translated in the various target languages. The quality of automated translation tools are good, but there is always a risk that the meaning of the text is not maintained in the translation. Therefore, a quality check for each text is necessary.
In contrast, with automated text generation, translation does not take place after generation, but is part of the text project. In these projects, data, logics, structure and variance of the text is processed centrally. The texts in different languages are generated out of one project.
Instead of making multiple copies of one text, on the the NLG Platform the semantic rules are created separately from the language and can therefore be applied to any language. Only the linguistic elements have to be adapted. Quality control is implemented centrally in the project.
These synergies mean that with AX Semantics, you can localize contents into multiple languages much faster.
Benefits of Automated Text Generation
 What are the benefits of multilingual automated text generation in comparison to the translation of texts (also machine translation)? The individual benefits are more or less pronounced depending on the size of the project, the number of languages and other factors specific to the particular use case.
What are the benefits of multilingual automated text generation in comparison to the translation of texts (also machine translation)? The individual benefits are more or less pronounced depending on the size of the project, the number of languages and other factors specific to the particular use case.
- Reduced cost for external translators.
- Less effort for managing translation processes.
- Ensured content conformity across languages (The text structure and message/statement of the copy is the same and can be quality assured for all languages).
- Working on several languages at the same time.
Preparing Multilingual Projects
Designing multilingual text projects spans content issues on the one hand and linguistic features on the other. The general questions to ask in this context are: In what ways will the content differ in various languages? To what extent does this affect the automated text project?
So first of all, it's necessary to describe the broad framework of the project. These initial considerations may even result in fewer languages being implemented first, or in certain parts of the text being excluded from automation because there are too many differences. In some cases you will decide to automate only a part of the content if the requirements are too different.
The framework of a multilingual project can cover, for example:
- Composing different content/stories (for different languages).
- Selecting products: Choosing only a part of the product range for each language.
- Checking out product names/licenses checks, think also about differing data/number formats.
- Taking into account legal questions for the generated text.
- Defining overarching target groups for the languages.
Preparing Your Data - What Should They Look Like?
Due to several languages being created in a common project on the NLG platform, and not produced by a translation after the output of the first language, this leads to special requirements for the form and structure of the data.
Same data structure - translated values
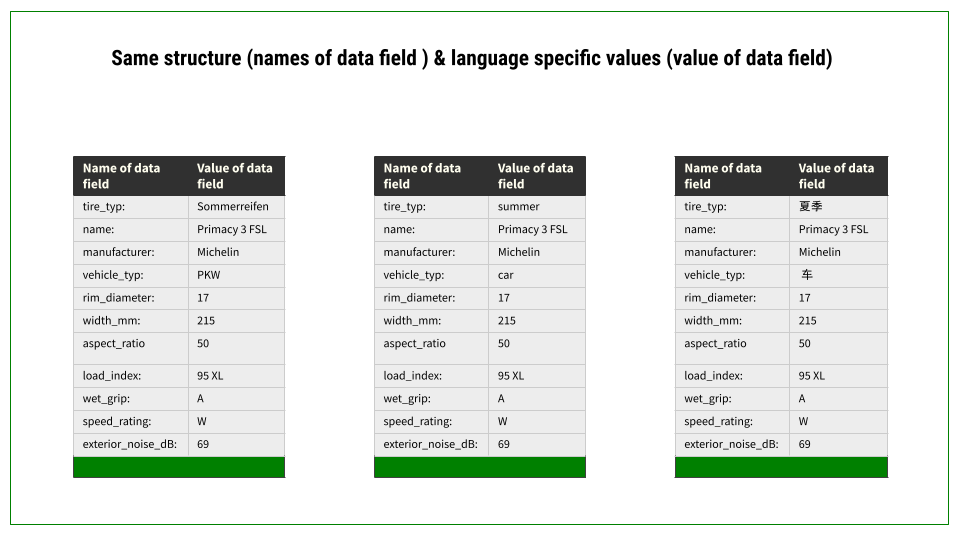
First of all, this applies to the language of the data. Data is not always language neutral. Of course, there are cases in which all the data available is in numbers, for example, and it therefore does not matter in which language the target text will be formulated. In most cases, however, there will be words or other values in the data that do not apply to all languages to be generated. Therefore, data has to be available in all target languages. So, if you don't have data in multilingual form, you have to translate the values.
The second important requirement applies to the structure of the data. To be able to set up the project properly, it is necessary that the data has the same, or at least very similar structure, in all languages.
This means, that the data must have the same data fields in all languages. Since all logic operation and relationships in the project, such as containers or triggers, refer to the data field names, the data fields must have the same name in all languages.
Working with Lookup Tables for translating data values?
In principle, it is possible to skip the translation of data before creating the project and to translate the data values via a Lookup Table. For this, one can use the same data for all languages and translate them within the project. This procedure only works as long as there are only a few data sets that need to be translated and if the data sets will not change.
As a rule, it is faster and less error-prone to translate the data in advance. Especially the maintenance effort afterwards is significantly lower.
Language settings are attached to Collections
The main language of each project is requested when the project is created. In a next step, you define in the project settings, the languages you want to have access to in this project. However, the properties that affect the data, as well as the language, are mainly organized in collections.
For multilingual projects, each language has to have its separate collection. When a collection is created, the corresponding language is selected from the very beginning.
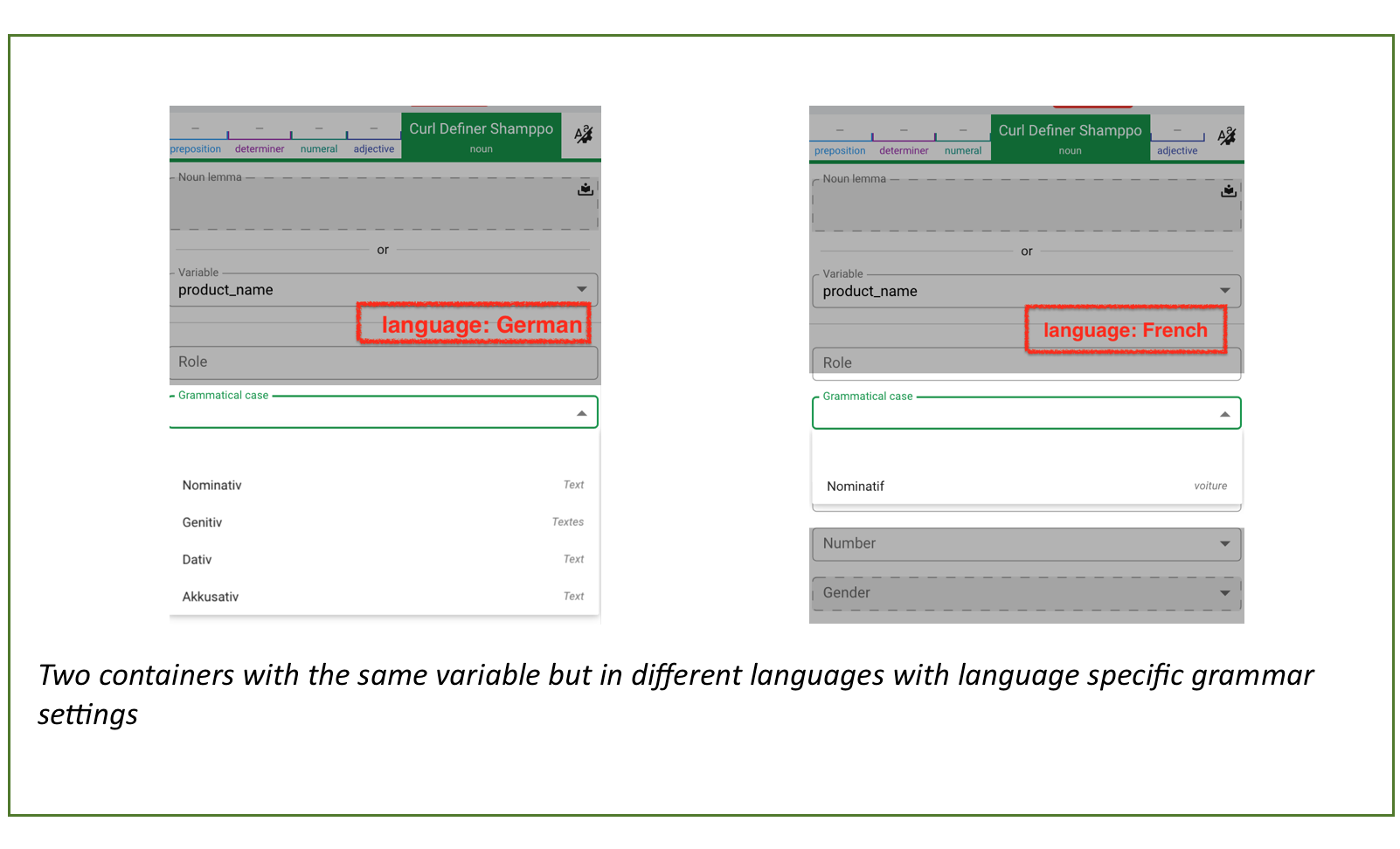
If you have assigned a language to a collection, the language modules for these languages are activated. That means:
- The software ensures the grammatical correctness of the content in the containers, with regard to the respective languages.
- You can set the respective language as preview language.
- You have language-specific selection options when configuring containers, such as pronouns, cases or grammatical genders.
WARNING
Once a collection is created, it's language can't be changed.
Please ensure the correct language is selected at creation time.
The Setup of Multilingual Projects
When managing multilingual projects, the first decision to be made is selecting the main language in which the project will be developed with conditions and logic, as well as, in which the copy will be composed. In this main language, the project is created in the same way as any monolingual project. Then, it is extended with additional languages, by creating the corresponding collections and translating the text parts.
- Copying Logic: Multilingual projects can be set up in such a way that the conditions and logic are developed in one language and then copied and adapted for a second (third, fourth, etc.) language. This works quite well, but can lead to additional maintenance effort, if changes are still made to the logic after copying in the main language.
- Managing centrally: The slightly different method of setting up the logic in a main language and applying it and the conditions, to the subordinated languages as well, has proven to be the most efficient way of handling multilingual projects.
TIP
The method of setting up the logic in a main language and transferring the logic and conditions to the subordinated languages has proven to be the most efficient way of handling multilingual projects.
Adjusting Collections for Centrally Managing Projects
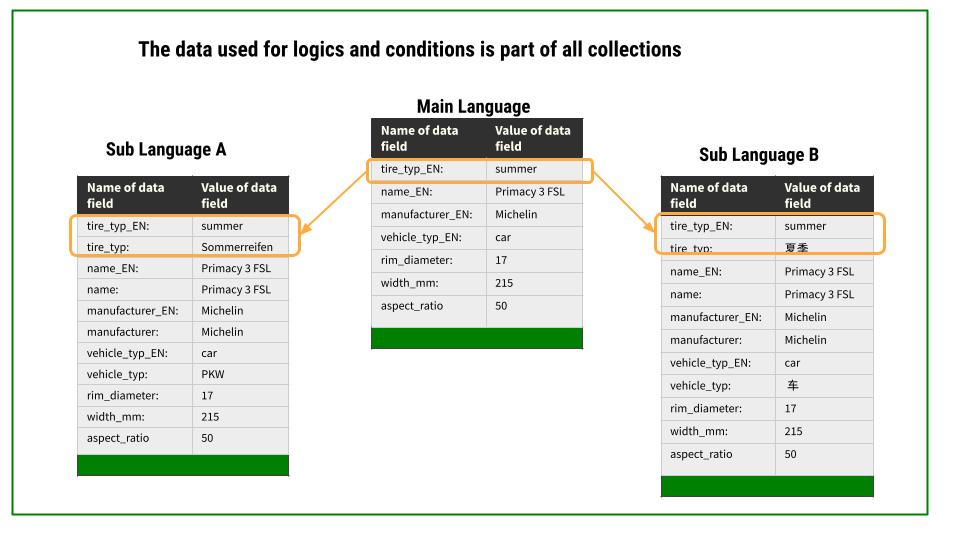
At the data level, this means that the data in each project within a collection must be available in the main language, as well as in the new language, so that the project runs without errors. While the values of the main language are used for processing the data within the project, the values of the target languages are then displayed in the text.
Adding Languages to the Main Languages within the projects
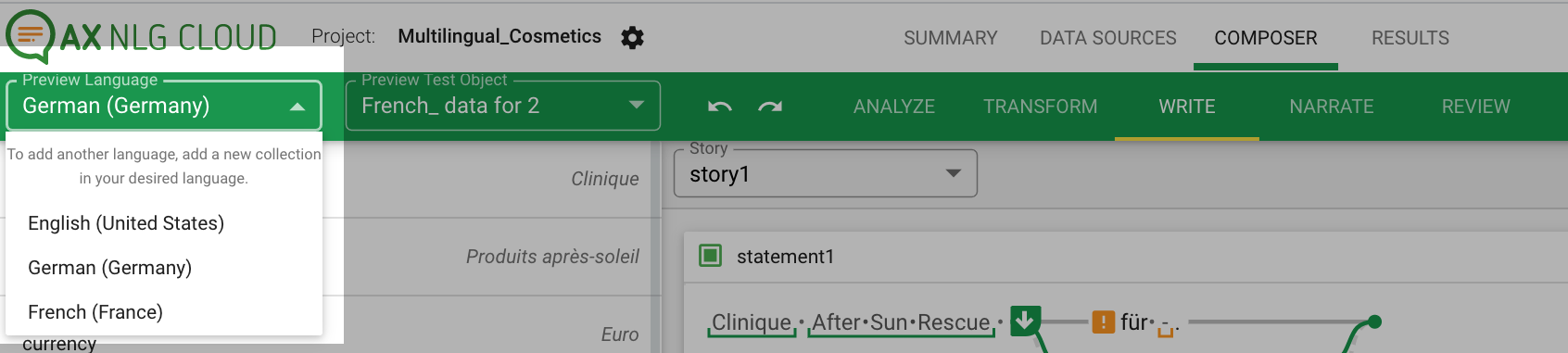
As soon as you have created the collection of the main language, work on your text project begins, which proceeds in the same way as for monolingual projects: You write your statements based on a test object and take care of the right calculations, logic and triggers in the Transform tab.
In the next step, you change the preview language and the Test object for the second language you want to use.
The Translating Process
Then the translation process starts: You translate Translation items: these are the parts of the project that are not built from variables or data. These are:
- Statements with Branches and Containers
- Phrases: If you have used Phrase nodes in your project to ensure grammatical correctness, the contents of the nodes have to be translated.
- Lookup tables play an important role in the translation of text generation projects, as they are often used to translate data content. However, they can also contain other linguistic content that needs to be translated.
To carry out the translation on the AX NLG platform, you can choose between two methods: a manual way and a more structured way using Translation Packages and Translate App.
1. The manual way with machine learning support:
This simple approach is well suited to smaller projects involving only a few people who all have access to the NLG platform. The procedure requires the statements to be translated into the target languages.
To do this, you can opt to use machine learning to help you translate statements: When you copy statements in the source language and paste them into the statement box in the target language, you can choose to have them automatically translated. In this case, the statement will be translated with all branches and containers using Deepl. Otherwise, the statement is pasted into the source language and you can translate it from scratch.
Translate the contents of phrases and lookup tables on the spot.
More details on machine-assisted translation: Machine Translation – let AI translate whole branching structures for you
2. The structured translation process using Translation Packages and the Translate App
With Translation Packages and the Translate App, there is a defined workflow for the translation work of generated text projects. This allows you to better manage and control the translation work. With this working method, translation tasks are outsourced to the Translate App: Translators can work on their translations in the Translate App without having to access the AX NLG platform. They also do not need to have in-depth knowledge of text generation.
The process is initiated on the NLG platform in the Translate tab, where the translatable items of a project's ruleset are created as translation packages for the Translate App. Once translated, these packages are merged back into the text generation project on the NLG platform.
The workflow can also support the translation without external translators, too:
- Translation into multiple languages simultaneously is easier to manage.
- Quality assurance of the translation is facilitated.
- The translation can already start, even if changes still need to be made to the text project. Even if working in parallel is not recommended.
For more details and more detailed instructions on working with Translation Packages, there is a separate guide: AX Translation Packages and Translate App: Getting Started
Multilingual Projects – Step-by-Step
Preparation
- Define your text concept for different languages.
- Customize your data structure according to your text concept and ensure consistency across languages.
- Translate your data values (if necessary).
On the platform
- Create your project with your main language collection.
- Define test objects for the main language.
- Run the analysis for the main language.
- Write your statements for your main language & define the logic and triggers.
- Check the results for the main language.
- Create your collections for the various languages
- Define a test object for testing each language.
- Translate the translation items.
Language specific adjusting
- Define the stories for each language (if necessary).
- Adapt Triggers, Branches or Logic for each language (if necessary).
Quality Assurance
- Check and review the results in each language.
What's Next?
- Learn more about multilingual projects in this webinar: How to Manage Multilingual Automated Content Generation Projects
- You can explore an example of a bilingual project: Newsstream Project English/German
- Take a closer look at translating with Translation Packages and Translate App: AX Translation Packages and Translate App: Getting Started