Guide to using the power of LLMs for your work on our NLG Platform
Writing with Large Language Models (LLMs) such as GPT, (Chat)GPT or BERT seems to be intuitive and simple: You create a prompt by entering keywords, whole sentences or a text briefing, or you provide the LLM with a text example and instruct it per prompt or chat to paraphrase or rewrite an issue.
Integrating LLMs into Data-to-Text work using our AX NLG platform goes one step further by combining these two new writing technologies. However, just using them in parallel by creating an entire text with the prompt optimization strategies on ChatGPT, for example, and then copying the results into the rulesets of your AX NLG text project can be very time-consuming. A better approach is to integrate suitable LLM components into the data-to-text system and thus utilize the strengths of both systems.
What you will learn in this guide
After reading this guide, you will:
- have an overview of how language models work
- understand the pros and cons of LLMs, both in general and for high-volume content production
- know at which point in the writing process you can use them
- know the difference between the approaches of Prompt Engineering and Data-to-text
- be able to work with the integrated LLMs of our NLG platform
Do you want to get started right away with the machine-learning powered assistants on our NLG platform?
Start here: The best of two worlds: Working with LLMs on our NLG Platform
Otherwise, read on to learn the fundamentals about LLMs.
Prerequisites: This is the World of LLMs and Writing
How do LLMs work?
LLMs are capable of handling a variety of text-based tasks and can therefore be used in various areas, where (semi-)automated text processing and/or production is desired, such as text summarization, analysis or editing. In the context of this guide, we only address text generation capabilities of LLMs.
1. LLMs are (pre)trained to predict the next word in a sequence
Large language models are trained on huge amounts of text taken from the internet to determine the probability of words within a sequence.
To do this, they are given tasks like being presented with a sequence of words and calculating the probabilities of the next word, or as a different task hiding words in the sequence and then making probabilistic suggestions to insert the hidden word.
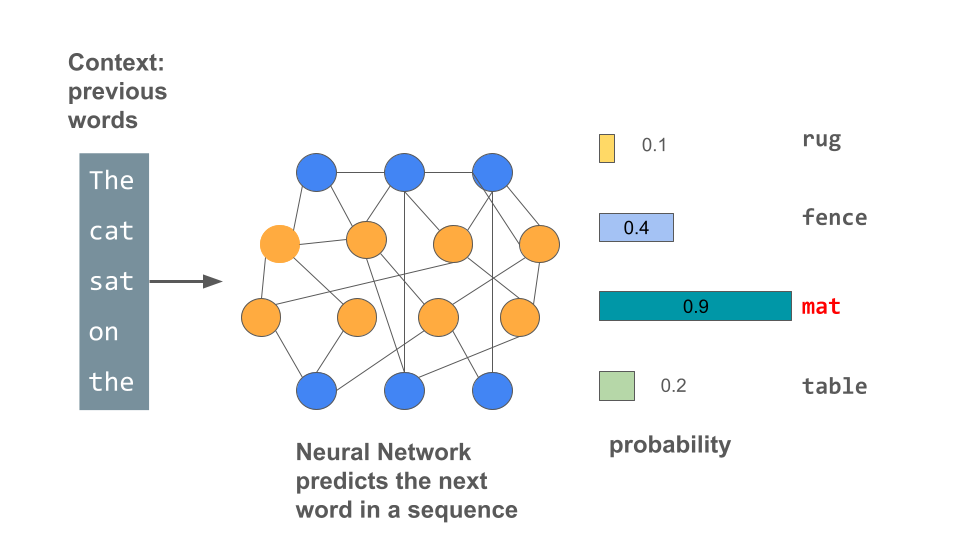 (click image to enlarge)
(click image to enlarge)
LLMs are limited, despite their enormous predicting capabilities:
a. Knowledge is not stored in a structured way
Training to predict the probability of the next word also means that the model succeeds in compressing the texts in some way. The result is that they can extract information from the internet sources on which they have been trained. So they do contain some sort of knowledge that includes, for example, facts.
However, these facts are not stored in a structured form, such as databases or knowledge graphs, so the information cannot be accessed in conventional ways.
b. Logical conclusions and generalizations are often tricky for LLMs
The reliance of the LLM on statistical patterns leads also to a significant gap in the model’s ability to make basic logical inferences and generalize knowledge.
If, for instance, a model that is trained on a sentence of the form "A=B", it will not automatically generalize to the reverse direction "B=A" – this phenomenon is called reversal curse.
Example If we (humans) know the sentence Olaf Scholz is the 9th Chancellor of Germany. (A=B), then we can answer the question Who is the 9th Chancellor of Germany? (B=A) The LLM is unable to do this.
Here is a famous example of this: ChatGPT correctly answered "What is Tom Cruise's mother's name?" ("Mary Lee Pfeiffer"), but could not answer "Who is Mary Lee Pfeiffer's son?
WARNING
Bear in mind that LLMs do not store knowledge in databases or in any other similarly structured form.
2. LLMs are later fine-tuned by humans to learn what they are expected to do
With an LLM that is only trained to output the next word in a sequence according to probability, you can't do very much in an application. Such a model would simply output documents. However, the aim is to further advance LLMs to become assistants that can answer questions or carry out tasks according to instructions. This is why there is a second training phase in which the models are no longer trained on random texts but on texts written or annotated by humans specifically for this purpose.
For example, people provide questions that other people answer in an ideal or very good way. Once there are enough such examples, the base model is fine-tuned using these examples. Further steps follow in which the model receives feedback, for example, on which of the generated answers is best. This way you get an assistant-like ChatGPT, which can be given tasks or precise text instructions.
The fine-tuning phase can be repeated many times.
What are the benefits of using LLMs for Writing?
LLMs are very powerful and revolutionary tools; prior to their breakthrough, such powerful language technologies were envisioned but not realized. Generating natural language and syntactically correct (longer) texts without using rules is already changing the way we handle texts and writing tasks.
One of the key qualities of LLMs is that they can solve a wide variety of different types of textual tasks. That is, they can be used for a very wide range of writing tasks in all stages of the copywriting process.
This applies to writing individual texts as well as to planning and writing an NLG text project.
When planning the text for inspiration or research
Here is one of the biggest strengths of LLMs: several studies have shown that just using these models increases inspiration and makes it much easier to find ideas. Especially in a phase where you are still looking for inspiration, trying things out, and going back and forth with ChatGPT is a good way to find new ideas or get a feel for how you want to write your text.
With all due caution about potential unreliability, you can also use LLMs for research. You can ask questions or ask for information, opinions, or arguments. The answers can also be incorporated directly into the text.
You should check the answers for accuracy before relying on them.
One of the strengths of LLMs is their ability to provide outlines or plans for different types of text, which you can use to plan your text, such as the agenda for a workshop, the structure of a product description, or a scientific paper. With the big LLMs, the time between creating an idea and turning it into text is extremely short. You can use them to test whether your ideas turn into good texts.
In the writing phase
When thinking about how to actually write the content, you can simply instruct the language model to write what you want it to write by giving it a text briefing. This is similar to briefing a copywriter: you specify the topic, style, length, and context of your text, and the LLM then generates the text accordingly.
In contrast to the inspiration phase, at this stage you usually already have a precise idea of what the text should look like and are able to formulate it: This is the stage where the design of the prompts will be particularly important.
To improve and revise a text
LLMs are good editors, they rarely make grammatical or spelling mistakes. You can instruct them to edit your text for various aspects; for example, to
- Correct spelling and grammar mistakes as well as add punctuation
- Remove any unnecessary words
- Change sentence structure to improve readability
- Break up longer sentences or paragraphs
One problem with this is that LLMs do not use a red pen to mark corrections, or make changes visible in a different way. Instead, they will return a corrected text. You will then have to compare this with the original text to retain control over your own text and only accept the changes that you think make sense. Instructing the model to output both the original and modified sentences, along with the reason for the changes, can be an aid here.
What are the drawbacks?
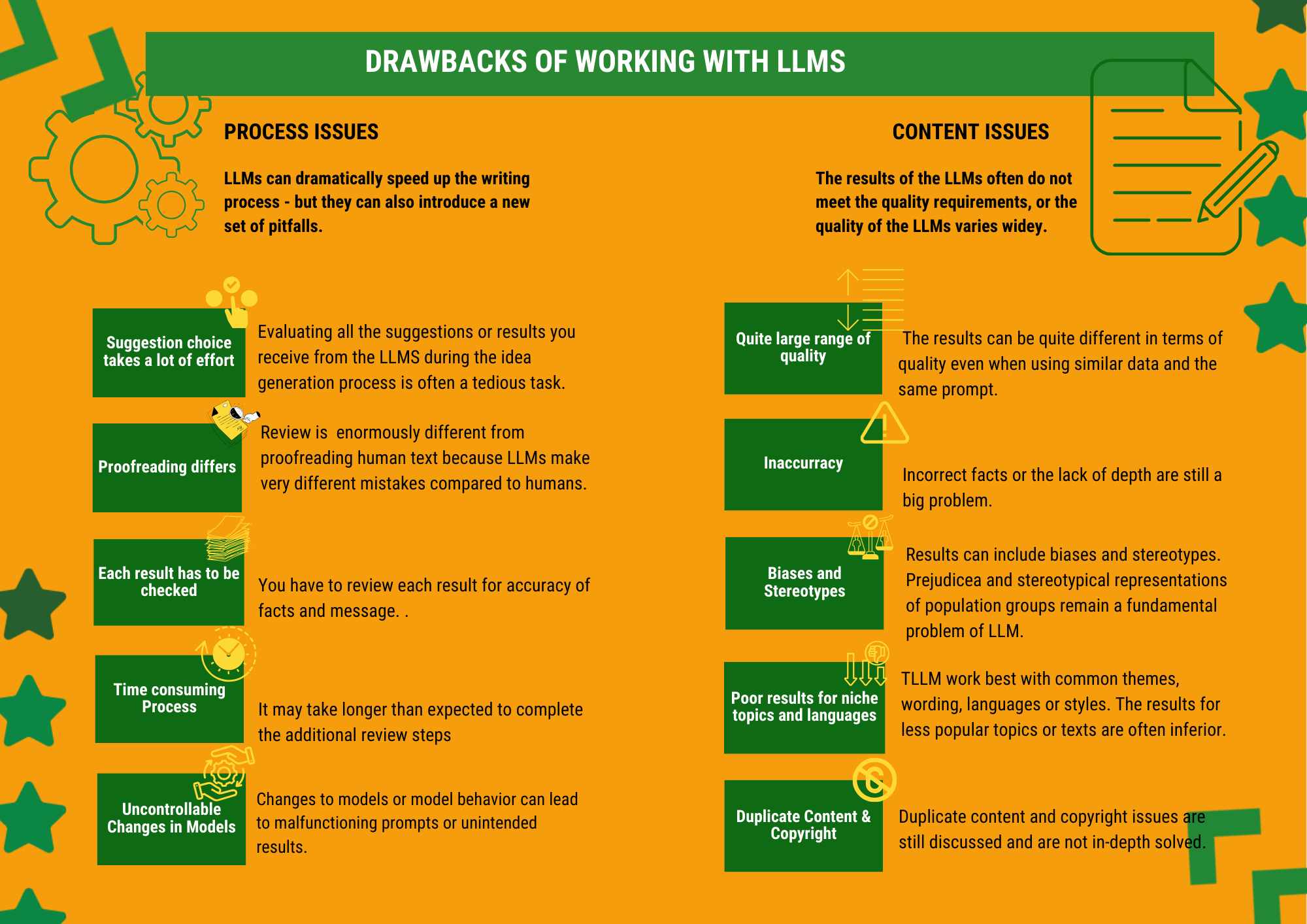 (click image to enlarge)
(click image to enlarge)
5 things you need to know to adjust your expectations
LLMs are best when they have no responsibility. If they are used to produce texts that are critical in some way, for example where liability cannot be ruled out or in the medical field, they are not particularly useful. This is because the result needs to be thoroughly checked at every stage.
Their strength lies in texts that are more superficially informative or entertaining, where the level of responsibility - and therefore the level of control - is not high.
LLMs work best with common themes, wording, languages or styles. The more familiar the topic or other text criteria are, the better the quality. The results vary considerably for texts with general or more specialized requirements. This is particularly noticeable for less common languages. However, it can even play a role for different product categories; for example, for well-known fashion products, they can produce significantly better and longer texts than for niche products.
LLMs are not experts. They have neither factual knowledge (which they cannot look up) nor experience in the fields. You will therefore need to keep the reins in your own hands and check the facts as well as any judgements, evaluations, or statements made.
Their strength is language. They make almost no grammatical or spelling mistakes and know an incredible number of variants for every phrase. Even without prompting, the result is usually easy-to-understand text, free from run-on sentences and incomprehensible use of nominalization.
You need to get familiar with the LLMs you use As with all tools, the more you practice, the better the results and the easier the work. Each of the LLM and their derivatives has its own special features and differences that you need to be aware of. Writing with LLMs is also different from conventional writing in more ways than you may initially think. You will write less of the actual text, but you will set out the features and requirements much more clearly, and you will spend more time skimming suggested texts and editing finished texts.
After learning these prerequisites, it is time to put them to use.
Data-to-text and LLMs: Different Approaches to Scaling
LLMs as Writing assistants and Prompt Engineering
In most cases, the LLMs function primarily as writing assistants, i.e. you write individual texts on specific topics or products and divide the work between humans and LLMs. Even if the LLMs do most of the actual writing work, many other writing tasks remain with humans: They set the intention and communication goal using the prompt and check the content, tonality, and structure. This then leads to a feedback loop in which the LLMs and the author keep passing the ball back and forth: whether the author revises or completely rewrites the prompt, or instructs the LLMs to revise the delivered suggestion.
The aim of this process can be to produce a good, appropriate, text. But it can also be to develop a prompt that can be used to commission several similar texts of (hopefully) the same quality. This involves refining the prompt to such an extent that only minor details need to be adapted for different texts, e.g. changing product characteristics. This process of developing the prompt as a model for one or more applications is known as Prompt Engineering. As OpenAI states in its documentation, it increases the quality of the text - in terms of meeting expectations - if as many specifications as possible are included in the prompt in different forms and instructions are clearly written:
- Provide any important details or context.
- Ask the model to adopt a persona, for example, "You are a content manager of a large e-commerce company".
- Tell the model about the target group.
- Provide examples of the desired result, such as a successful product description.
TIP
- A prompt is an instruction to an LLM.
- Prompt Engineering is the practice of finding the best prompt methods to get the requested results from the LLM.
Using LLMs for Generating large numbers of product descriptions
With prompt engineering, it is certainly possible to use LLMs to produce a large number of texts, but it definitely requires strategic planning and involves a great deal of work.
Here are issues that need to be considered during such an LLM based production process:
| Strategic Decisions | You need to make some strategic decisions about how to segment your product, deciding which product groups can be covered by a single prompt. |
| Data Checking | For the prompts to work, the data must be well maintained. Incomplete data, for example, can lead to varying or even wrong output and is hardly predictable. |
| Technical Settings and Integration | You have to decide how to handle technical settings and aspects, like managing accounts for testing and production, integration with CMS or E-commerce platform |
| Prompt Design | You may need to develop multiple prompts for relatively small product groups until the results are satisfactory - including a potentially time-consuming fine-tuning process. |
| Testing | Intensive testing is required and quite time-consuming. Firstly, there is the fine-tuning of prompts mentioned above. Then there is the testing of the prompts with different product data to get an idea of the accuracy. |
| Output Handling | Determine how to handle the model's output. You may need to post-process the generated text to ensure it meets your style and quality standards. This could involve filtering, summarization, or other techniques. |
| Quality Control and Review Process | Implement a standardized quality control process to ensure the generated descriptions meet your standards. Instruct human reviewers to validate and, if necessary, edit the content for accuracy, coherence, and style. |
| Documentation and Training | The entire process has to be documented, including data preparation steps, model training procedures, and integration guidelines. You need to provide training to relevant teams, including content creators, reviewers, and technical staff. |
| Cost Management | The cost calculation is somewhat complicated as the costs are linked to tokens. Therefore, the cost is hard to predict. |
| Security Aspects | You have to give your data to a service that is very intransparent about how they use them. |
Differences between Generating Texts with LLMs or based on a Data-to-Text System
If you have already used AX or have completed the AX Seminar, you will be familiar with the main steps in a Data-to-Text project and the necessary tasks involved in the project: uploading and analyzing data, creating a text concept, creating the rule set and writing the statements including variants. Finally, there is a central quality control of the project. The whole process is structured and the aim is to create a blueprint for the text with the associated data. This is a clear contrast to authoring using LLMs as described above.
 (click image to enlarge)
(click image to enlarge)
Writing: Proof-reading each text from an LLM vs centralized control with Data-to-text systems
The main problem with producing large volumes of text using LLMs is that, regardless of the strategy used to create the prompt and the effort put into fine-tuning it, in order to achieve error-free texts and consistent quality of content and style, each copy needs to be read, and corrected if necessary.
This is because of two reasons
- The results of language models are non-deterministic by default (i.e. the output of the model can vary from query to query). Ensuring that all the parameters, such as prompt or temperature, are the same may help, but consistency is still not guaranteed. Even if you test your prompt with the same dataset, results may vary.
- Furthermore, the determinism of results may be affected by changes that large language companies make to the model configurations. And you don't know how these changes will affect your results.
This means that every single text has to be checked and the prompts have to be updated regularly.
In contrast, the results of our NLG platform are easy to control: You can check the text project for errors or undesirable behavior in advance using various methods. The errors can then be corrected centrally, and the individual texts that are generated will always consistently follow the specifications of the rules in the project.
Updating: New creation cycle with LLMs vs (partly) automated update cycle with Data-to-Text Systems
Similarly, text updates are much more time-consuming with LLMs because each text has to be checked individually again, whether it is a minor product change or a major rewrite.
With a Data-to-Text system, updates happen automatically when the data changes. If changes are required, they are made within the project and only need to be checked once.
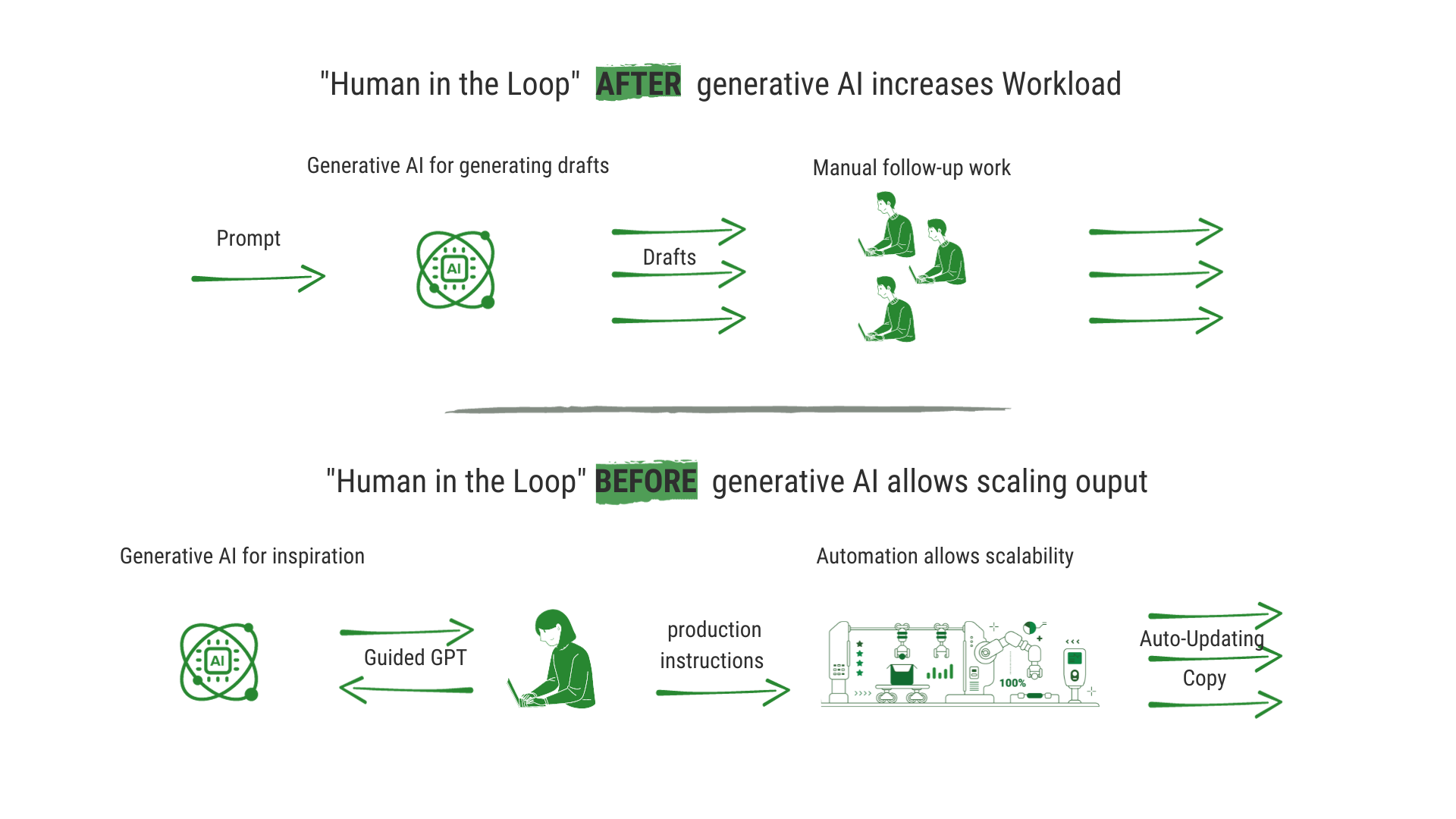 (click image to enlarge)
(click image to enlarge)
Side-by-Side Use of External LLMs and Data-to-Text Solutions
Besides the writing of single texts or the attempt to generate a series of texts in quick succession, LLM can be used in a different way, i.e. primarily as a source of inspiration or as a formulation aid for the generation of data to text on our NLG platform. Compared to solely using LLMs, working side-by-side with GPT has two main advantages:
- There is no need for time-consuming testing of prompts with different data sets. This is because our platform ensures that the data is correct and that there are no discrepancies between the Containers and the Transformer.
- Final quality assurance of each text is no longer required.
Here are a few ideas for the complementary use of LLMs for data-to-text generation:
- For planning, research and inspiration:
- Ask the LLM what information is stored in your data
- Clean up your data with LLMs
- Get ideas for product features and benefits
- For writing: Using the LLM to write one or more source texts
The best of both worlds - working with LLMs on our NLG platform
The simplest and safest way to use LLMs for text generation is to use the built-in features of our platform. The advantage is that you don't have to switch between applications and the results can be incorporated directly into the project. Most of the text work for generation takes place directly on our NLG platform once the planning phase is complete and the data-to-text project is set up.
So that there is no disruption to this work, the ML components have been integrated where they are most useful: This is mainly in the Write tab, where the language realization work is done.
There are three types of writing support for LLMs (these are expanded upon below):
- GPT selects and provides insight into the most important data points to help you prioritize your work.
- An LLM suggests your next statement based on your data and the text you've written so far (Statement Suggestions)
- You can have alternative formulations suggested to you (Alternative Text Suggestions)
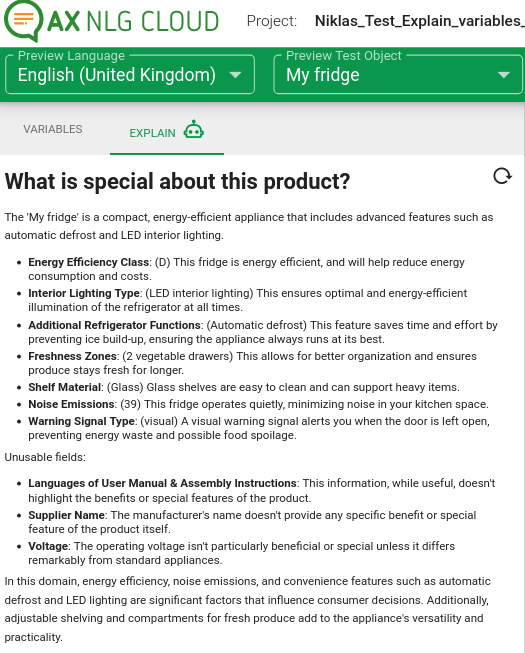
Explain variables - Topic research for inspiration and context
Explain variables helps you in getting an idea on what to prioritize in your story telling. Your data attributes of a product are analyzed to find the most important data attributes for that specific product type. A short explanation, outlining the product benefits for a potential buyer, is intended as an inspiration on how to communicate the product advantages. You also get a list of attributes that are not relevant so you can make sure to focus on the information that matters most.
Statement Suggestions – helps you to keep the story going
Suggested Statements allow you to gradually build your text in cooperation with the LLM. Below the Statements you have already created, you will receive a suggestion for another Statement that fits into your existing Story. The suggested Statement is based on your input in regard of its title, intended style, selected product data attributes and the text you have written so far. Finally, selecting example data sets spotlights on product variations that deserve special mentioning. You can either accept the suggested Statement in its entirety or modify it. The Container Suggestions are also very useful here, as they allow you to easily create the containers you need.
The prompts sent to the LLM are tailored to three important factors
- The text genre product descriptions. This means that content factors such as describing features and benefits and friendly customer approach are sent as briefings.
- The variables of the text project or the underlying product data. The data of the current test object is relevant here. Just like what you write yourself in the Write tab, the LLM proposal is also based on the test object. You can therefore influence the direction of the new statement by selecting different test objects.
- Your text written so far. Everything you have written before is available to the LLM. This will give the LLM more information about the context and the style of your text and will allow the LLM to tailor the suggestion to it. It also helps to avoid duplication in the text.
TIP
If you want to provide more immediate direction, with the statements Statement title you can set topic and intention and a style hint gives your story telling a clear direction.
Alternative Text Suggestions
Alternative Text Suggestions provide synonyms for words and rewrites phrases or entire sentences that you select. You are given up to 10 suggestions, and the ones you accept are immediately created as distinct Branches. In this way, you can increase the variance of your texts and make them less similar to one another.
Translation
Translation is also an important area of use for neural networks similar to LLMs - AX gives you the option of using DeepL directly on our platform or in the Translate application. For more information on machine learning assistance in translation and translation in general, see:
- "The Translating Process" chapter in the Multilingual Projects Guide
- The Chapter "How to translate on the Translate App" in the "Getting Started" Guide of the AX Translate App documentation.
Large Language Model options on our AX NLG Platform: GPT-3.5 or GPT4
Both our new ML-powered features are backed by OpenAI's GPT API, which is one of the most advanced large language models available today. The GPT API lets us generate text based on your project's active test object, variables and the text you have already written. This ensures that you only get customized text that matches your content. You can select either GPT-3.5 (ChatGPT) or GPT-4 in the project settings.
In contrast to ChatGPT, OpenAI will not use API data to train OpenAI models (see their API data usage policies).
Data Privacy
OpenAI may receive rendered content of statements, name and output value of variables, and contents of the selected test object. They will not receive any intermediate values and ruleset code. Should you still not want us to send your project data to OpenAI, you can opt out of OpenAI or deepL features per project in your project settings.
How to get the ML-Powered Suggestion Tools
EnableML-powered Suggestions in your Advanced Settings. If you don't want to use the new GPT features, you can easily opt out by unchecking the External Service Providers boxes.
TIP
Container or Variable suggestions are still active when these services are disabled.
Available Languages
ML-powered suggestions are currently available for the following languages:
Bulgarian (bg-BG), Catalan (ca-ES), Chinese (zh-*), Croatian (hr-*), Czech (cs-*), Danish (da-DK), Dutch (nl-*), English (en-*), Finnish (fi-FI), French (fr-*), German (de-*), Greek (el-GR), Hungarian (hu-HU), Italian (it-IT), Japanese (ja-JP), Korean (ko-KO), Latin (la-VA), Lithuanian (lt-LT), Macedonian (mk-MK), Norwegian Bokmål (nb-NO), Polish (pl-PL), Portuguese (pt-*), Romanian (ro-RO), Russian (ru-RU), Serbian (sr-RS), Slovak (sk-*), Slovenian (sl-SI), Spanish (es-*), Swedish (sv-SE), Ukrainian (uk-UA).
Further Reading
A few more details about the integrated LLMs: ML-powered Suggestions – Transforming Your Writing Process with GPT
What do you want to do next?
Learn more about how GPT-powered writing of product descriptions: