General Concepts of the NLG and the Platform (Intro)
The AX NLG Cloud is a platform on which human-readable texts can be generated from structured data. The resulting texts are domain-independent and not limited to any particular genre of text. Currently, more than 110 languages can be generated with the platform.
TIP
Natural Language Generation, a subfield of artificial intelligence (AI), is a software process that automatically transforms data into written or spoken language. NLG is related to computational linguistics, natural language processing (NLP) and natural language understanding (NLU), the areas of AI concerned with human-to-machine and machine-to-human interaction.
Components of the NLG Platform
The NLG platform provides complete end-to-end functionality for NLG projects. All functions are available as a web-based self-service tool. It allows you to access functions such as data transfer, text generation as well as to integrate automated content creation into your website. The infrastructure enables parallel processing of all user and AI inputs on the client-side and server-side, which are then synchronized in real-time.
- The NLG Cloud Cockpit is a multi-user collaborative web interface with user management and data connection
- The Composer area for configuration of the project, including data extraction and analysis, visual data transformation, document planning and surface realization.
- The Lexicon is a tool accessible in the Composer area of the NLG platform. It holds the grammatical information in a project about particular words that the software needs to generate linguistically correct units.
- Via our API at api.ax-semantics.com all functionality of the platform is accessible to ensure easy integration into other platforms and systems. (see API references)
Accessing the Software (Cockpit)
The web interface is a self-service portal integrated into the NLG Cloud. From here you have access to functionality such as data transfer, text generation and integration of automated content generation into your website. cockpit.ax-semantics.com
Processing Steps of NLG Projects
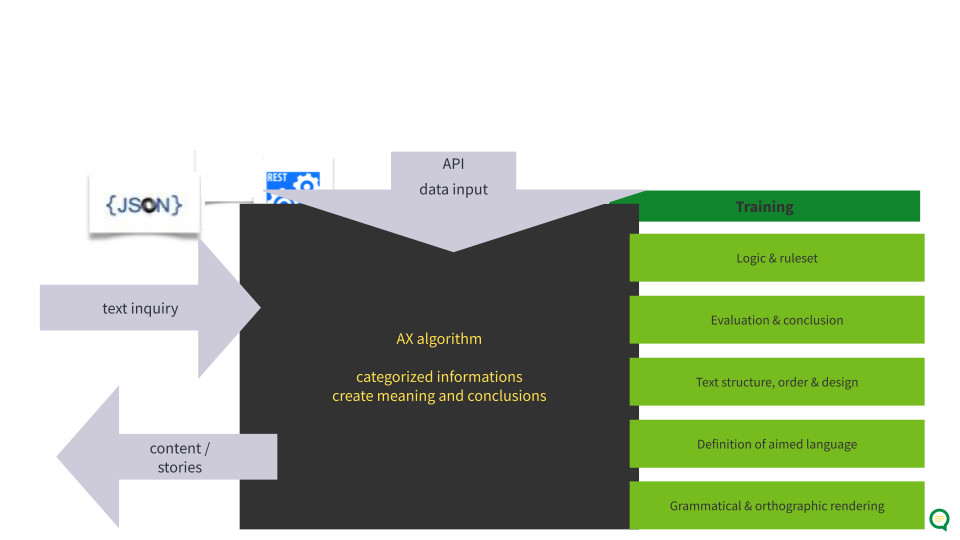
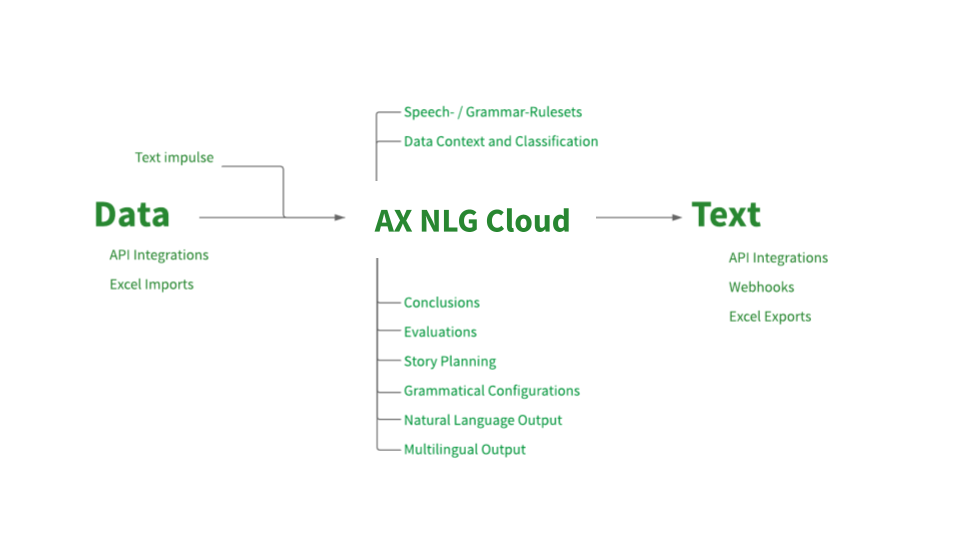
Structured Data as a requirement (Data Source)
The text generation on the AX NLG Platform is based on structured data. Structured data means that data is provided in separate data fields, you cannot use unstructured data like continuous text as a data source. For further processing, the data is analyzed and prepared. These analyses provide you with an evaluation of the data, such as the distribution of the values. Data is uploaded whether via API or manually (CSV, JSON and XSLX) on the NLG platform.
Data Analysis (Analyze)
By running an Analysis the data values are classified to get an overview of the distribution of data types, values and numbers.
See also Analyze
Story Planning and Text Conception (Narrate)
An essential step in text generation is the planning of the overall text. Decisions on the content and structure of the text are made. Based on domain and application knowledge, it is determined which information will suit the communication goals.
The planning of the entire text takes place in the Narrate area, where text structures can be arranged in stories and the sequence of information can be specified.
See also Narrate: Stories and Loops
Conclusions and Reasoning (Transform)
Relevant information in the data is extracted and put into formal rulesets. For this data can be mapped to edit strings, Out of these statementsConstructing logical statements and connecting them into a text structure Grammar rendering (morphology, syntax)
See also Transform
Grammar, Morphology and Syntax Realization (Write)
In the ruleset, you can access your data and create logical evaluations about it. You can also define which words should be used for the outcomes of those evaluations.
Languages
The AX NLG Cloud is aimed at multilingual applications. For details of the specific features of the various languages, see the Language References
Currently, we support the following languages and regional variants in our self-service interface:
- az-AZ: Azerbaijani (Azerbaijan)
- be-BY: Belarusian (Belarus)
- bg-BG: Bulgarian (Bulgaria)
- ca-ES: Catalan (Spain)
- cs-CZ: Czech (Czechia)
- da-DK: Danish (Denmark)
- de-AT: German (Austria)
- de-CH: German (Switzerland)
- de-DE: German (Germany)
- de-LU: German (Luxembourg)
- el-GR: Modern Greek (Greece)
- en-AU: English (Australia)
- en-CA: English (Canada)
- en-GB: English (United Kingdom)
- en-IE: English (Ireland)
- en-NZ: English (New Zealand)
- en-SG: English (Singapore)
- en-US: English (United States)
- en-ZA: English (South Africa)
- es-AR: Spanish (Argentina)
- es-BO: Spanish (Bolivia)
- es-CL: Spanish (Chile)
- es-CO: Spanish (Colombia)
- es-CR: Spanish (Costa Rica)
- es-EC: Spanish (Ecuador)
- es-ES: Spanish (Spain)
- es-GT: Spanish (Guatemala)
- es-MX: Spanish (Mexico)
- es-PA: Spanish (Panama)
- es-PE: Spanish (Peru)
- es-UY: Spanish (Uruguay)
- et-EE: Estonian (Estonia)
- fi-FI: Finnish (Finland)
- fr-BE: French (Belgium)
- fr-CA: French (Canada)
- fr-CH: French (Switzerland)
- fr-FR: French (France)
- fr-LU: French (Luxembourg)
- hi-IN: Hindi (India)
- hr-HR: Croatian (Croatia)
- hu-HU: Hungarian (Hungary)
- id-ID: Indonesian (Indonesia)
- is-IS: Icelandic (Iceland)
- it-CH: Italian (Switzerland)
- it-IT: Italian (Italy)
- ja-JP: Japanese (Japan)
- ka-GE: Georgian (Georgia)
- kk-KZ: Kazakh (Kazakhstan)
- ko-KR: Korean (South Korea)
- la-VA: Latin (Vatican City)
- lb-LU: Luxembourgish (Luxembourg)
- lo-LA: Lao (Lao)
- lv-LV: Latvian (Latvia)
- lt-LT: Lithuanian (Lithuania)
- mk-MK: Macedonian (North Macedonia)
- ms-BN: Malay (Brunei Darussalam)
- ms-MY: Malay (Malaysia)
- mt-MT: Maltese (Malta)
- nb-NO: Norwegian Bokmål (Norway)
- nl-BE: Dutch (Belgium)
- nl-NL: Dutch (Netherlands)
- pl-PL: Polish (Poland)
- pt-BR: Portuguese (Brazil)
- pt-PT: Portuguese (Portugal)
- rm-CH: Romansh (Switzerland)
- ro-RO: Romanian (Romania)
- ru-RU: Russian (Russian Federation)
- se-FI: Northern Sami (Finland)
- si-LK: Sinhala (Sri Lanka)
- sl-SI: Slovenian (Slovenia)
- sk-SK: Slovak (Slovakia)
- sr-RS: Serbian (Serbia)
- sv-SE: Swedish (Sweden)
- sq-AL: Albanian (Albania)
- ta-IN: Tamil (India)
- ta-LK: Tamil (Sri Lanka)
- th-TH: Thai (Thailand)
- tl-PH: Tagalog (Philippines)
- tr-TR: Turkish (Turkey)
- uk-UA: Ukrainian (Ukraine)
- uz-UZ: Uzbek (Uzbekistan)
- vi-VN: Vietnamese (Viet Nam)
- zh-CN: Chinese (China)
- zh-HK: Chinese (Hong Kong)
- zh-MO: Chinese (Macao)
- zh-SG: Chinese (Singapore)
- zh-TW: Chinese (Taiwan)
- zu-ZA: Zulu (South Africa)
Additionally, the following languages are supported as well, please contact our support team to get these unlocked in your account:
Adyghe, Albanian, Armenian, Asturian, Azeri, Bashkir, Basque, Bengali, Breton, Crimean-Tatar, Faroese, Friulian, Galician, Haida, Hebrew, Kabardian, Khaling, Kurmanji, Ladin, Livonian, Lower-Sorbian, Navajo, Neapolitan, Norwegian-Nynorsk, Occitan, Pashto, Persian, Quechua, Sanskrit, Serbo-Croatian, Sorani, Swahili, Tatar, Venetian, Votic, Welsh, Yiddish, Kannada, Cornish, Greenlandic, Karelian, Kashubian, Khakas, Mapudungun, Murrinhpatha, Norman, Scottish-Gaelic, Telugu, Tibetan, Turkmen