Enhanced overview – Automatically naming your parameters
In the past Naming Parameters was both indispensable to keep track of your work and oftentimes skipped as the impact was not immediately apparent. Now mapping and condition nodes are automatically naming the created parameters after the connected node. Also both of these node types now have the same reactive input port as the group node: when you connect to the first port and a new one is automatically created. As a result, you can now create automatically well-named parameters simply by connecting input node after input node.
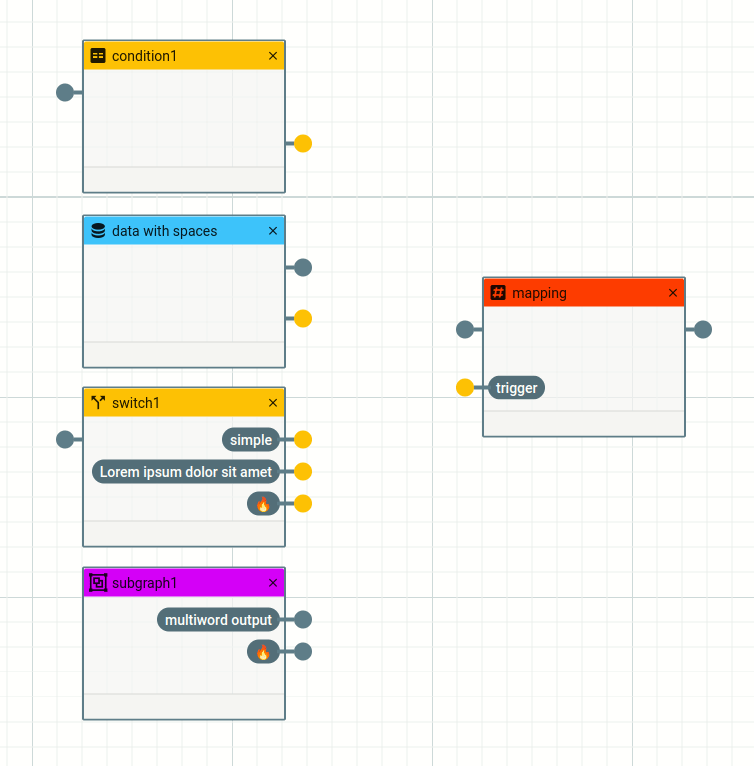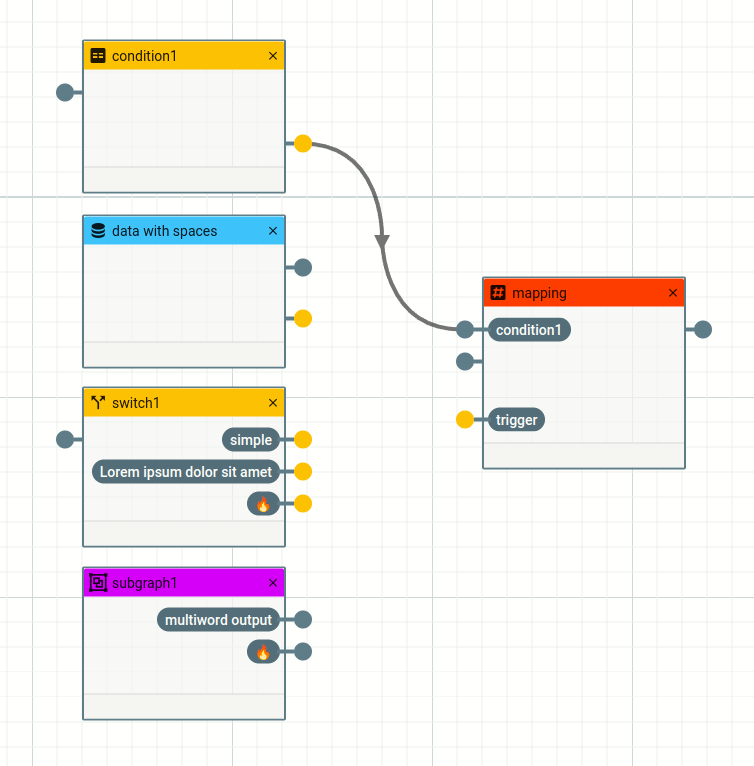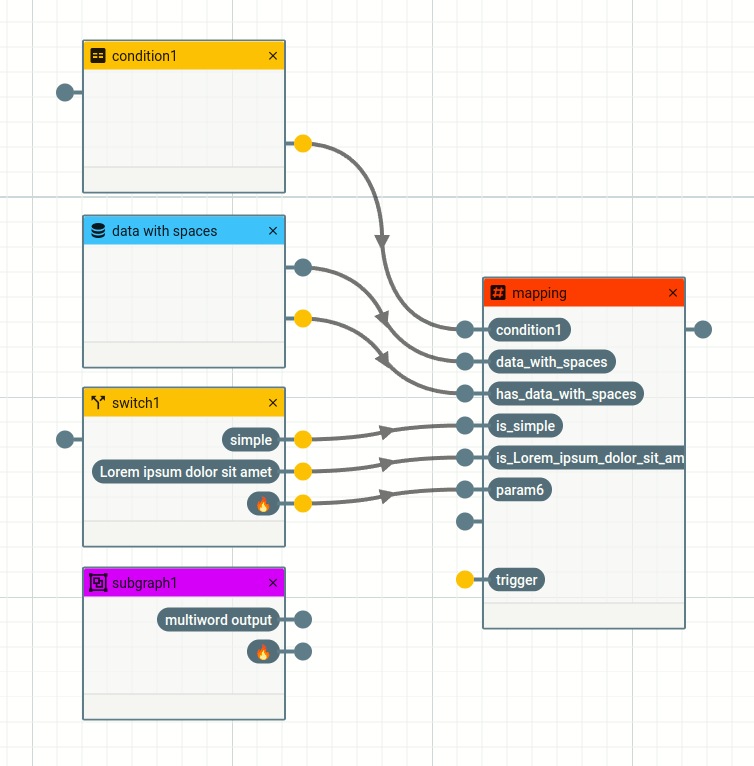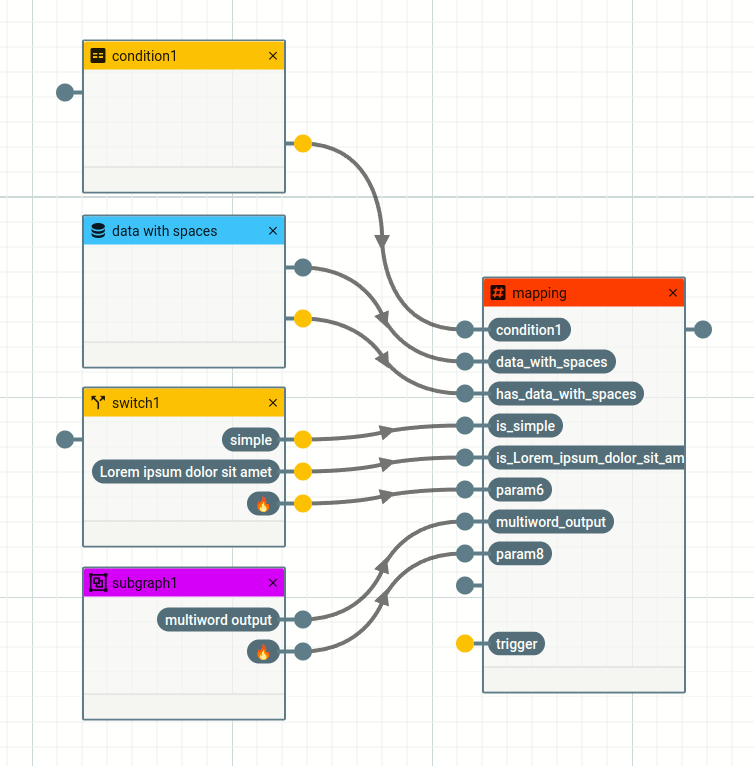
This feature is available in all your rule sets.
Naming Scheme
The name chosen for a newly created parameter is the name of the connected node.
One exception is the yellow data node port. In that case a "has_" is added to show that this input port checks whether the data node is empty or not. This way those special ports are easier to determine. Other conditions usually have more customized checks, the condition nodes name is taken as a parameter name.
Another exception is the switch node result, which is prefixed with an "is_" and the text you have chosen as your case.
Special characters
You have more character types available in the node name (i.e. spaces, emojis, ...) than are permitted while naming parameters. To make sure that all generated parameter names are usable within the node, spaces and other characters are replaced with underscores ("_"). More exotic characters like emojis in the node name default back to the usual #param1 naming as there is not good way to translate here.
Subgraph line wrapping
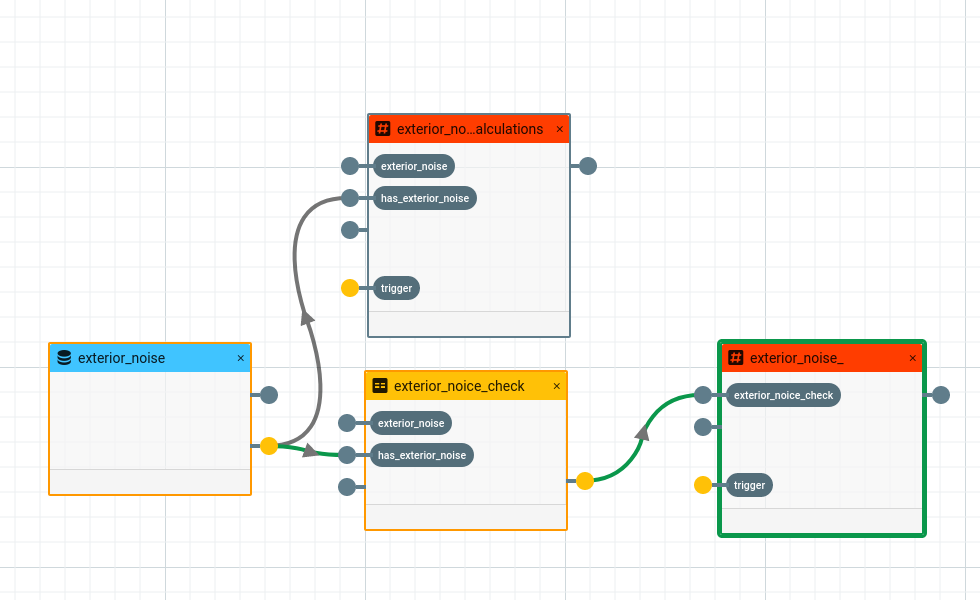
Because transformation node names can get as elaborate as the underlying data processing step, it can very well happen that the generated parameter name does not completely fit into the node box. Additionally there are node types like subgraphs, which have two opposite sides where parameters can be created.
Currently parameter names are truncated in the middle of the node to fit everything into these nodes.